一文看懂随机森林
随机森林是一种由决策树构成的集成算法,在很多情况下都能有不错的表现。本文将介绍随机森林的基本概念、4 个构造步骤、4 种实现方法的对比评测、10 个优缺点和 4 个应用方向。
什么是随机森林?
随机森林属于集成学习中的 Bagging(Bootstrap AGgregation 的简称)方法。如果用图来表示它们之间的关系,则随机森林属于集成学习中的 Bagging 方法。

决策树 – Decision Tree
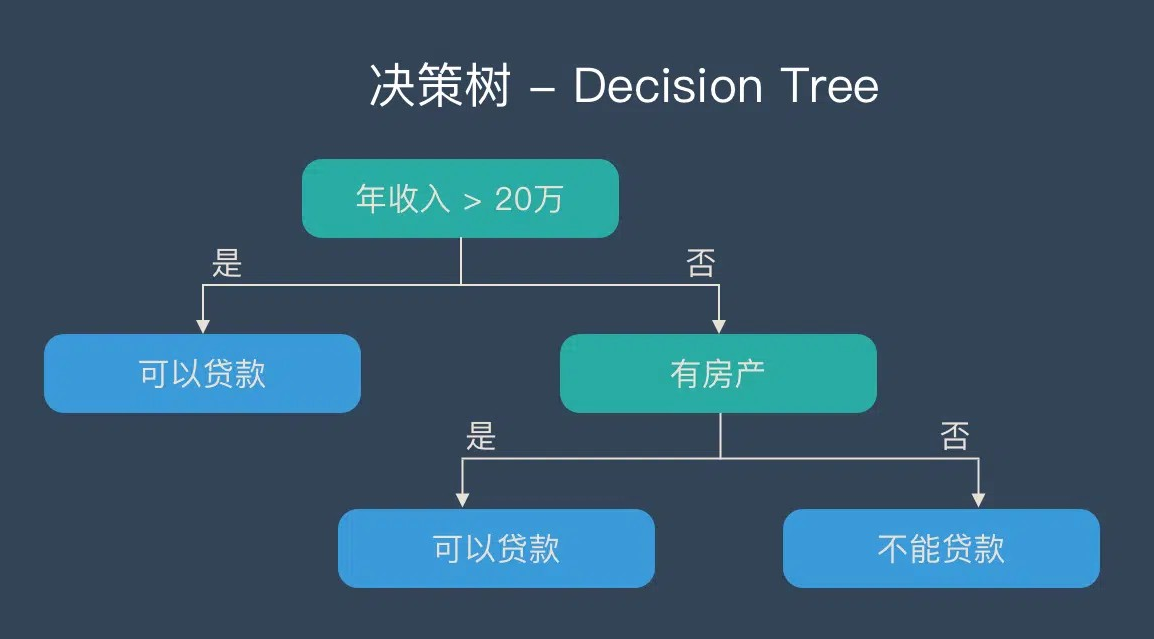 决策树是一种简单、解释性强且符合直观思维的算法,是基于 if-then-else 规则的有监督学习算法,上述图片可以直观地表达决策树的逻辑。
决策树是一种简单、解释性强且符合直观思维的算法,是基于 if-then-else 规则的有监督学习算法,上述图片可以直观地表达决策树的逻辑。
随机森林(Random Forest | RF)
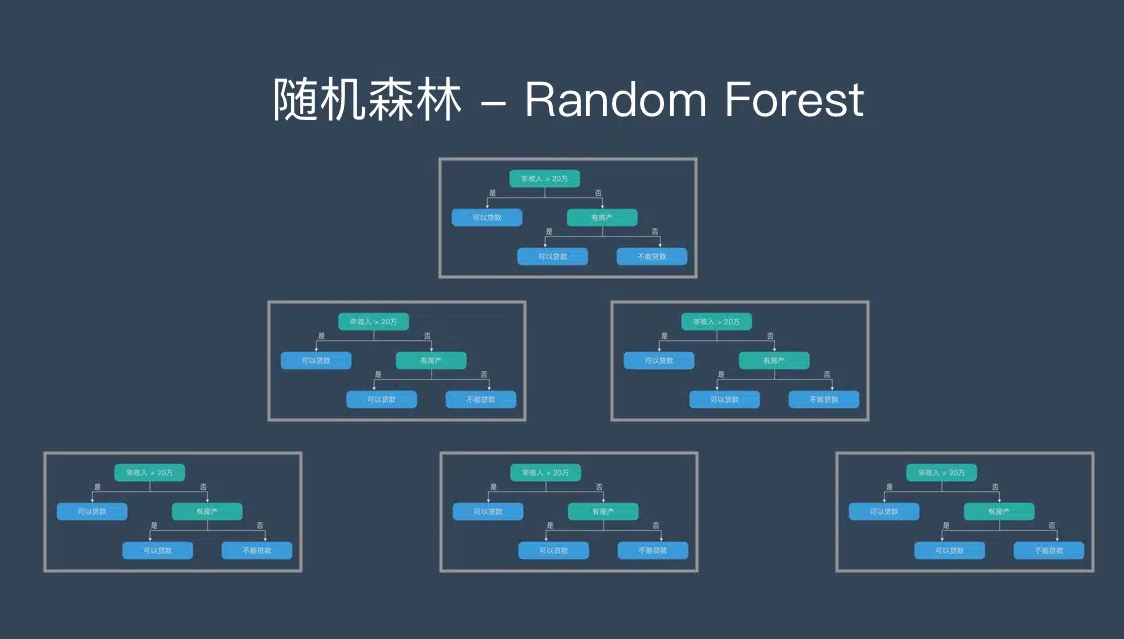 由多个决策树构成,不同决策树之间彼此独立。当新的样本进入时,每棵决策树分别判断分类,最终以多数投票的结果作为随机森林的输出。
由多个决策树构成,不同决策树之间彼此独立。当新的样本进入时,每棵决策树分别判断分类,最终以多数投票的结果作为随机森林的输出。
构造随机森林的 4 个步骤

构造随机森林主要包括以下 4 个步骤:
- Bootstrap 抽样: 对样本容量为 N 的数据集,有放回地抽取 N 次,每次抽取 1 个样本,得到 N 个样本作为决策树的训练数据。
- 特征随机: 当每个样本有 M 个属性时,在每个节点分裂时,随机从 M 个属性中选取 m 个属性(m << M),然后根据信息增益等策略选择最佳分裂属性。
- 决策树构建: 按照步骤 2 进行每个节点的分裂,直至无法继续分裂(整个过程中不进行剪枝)。
- 结果聚合: 重复步骤 1~3 构建大量决策树,随机森林最终通过多数投票方式汇总各树结果,给出最终预测。
随机森林的优缺点
优点:
- 能够处理高维数据,无需额外降维和特征选择。
- 可评估特征的重要性,并揭示不同特征之间的相互关系。
- 不容易过拟合,训练速度较快且易于并行化。
- 对不平衡数据集具有一定平衡误差的能力。
- 即使部分特征缺失,仍能保持较高准确率。
缺点:
- 在噪声较大的问题上可能会过拟合。
- 对于取值较多的属性,其影响可能被放大,导致属性权值不够可信。
随机森林 4 种实现方法对比测试
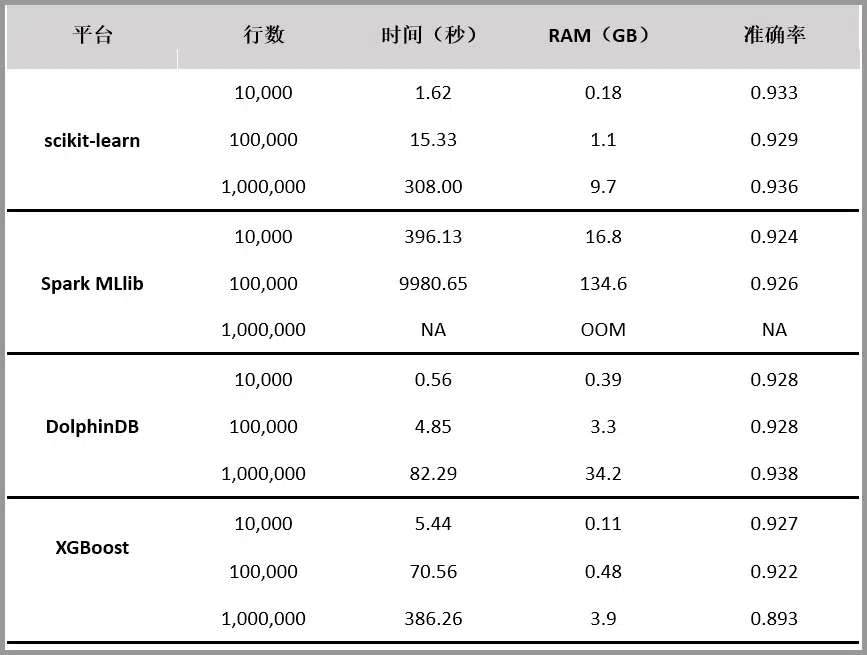
随机森林既可用于分类,也可用于回归。本文对 scikit-learn、Spark MLlib、DolphinDB、XGBoost 四个平台的随机森林实现进行对比, 评价指标包括内存占用、运行速度和分类准确性。
测试结果如下:
【随机森林 4 种实现方法对比测试示意图】
随机森林的 4 个应用方向

随机森林可以应用于:
- 离散值的分类
- 连续值的回归
- 无监督学习聚类
- 异常点检测
百度百科+维基百科
更多详情请参考百度百科和维基百科相关条目。
扩展阅读
详细了解随机森林,请参考文章《一文看懂随机森林》。
发表评论